Detection of the signal of selection from genome scan. Population based analysis
Introduction
The purpose of the vignette is to detect outlier SNP loci from a large number of SNPs genotyped for a large number of individuals. Individuals are organised in well defined populations. Then, we tested if allele counts in outlier loci are correlated to the temperature. We will first use a method based on principal component analysis (PCAdapt) (section 2) and a second method based on atypical values of Fst (OutFLANK; Whitlok and Lotterhos (2015); https://github.com/whitlock/OutFLANK) (section 3) to detect outliers loci. Then, we will test if the allele counts in outliers are correlated to the temperature using a Poisson regression (section 4).
Assumptions
- We assume that loci are neutral and we are looking for those are deviant from the neutral assumption.
- We assume that loci correlated to the environment (temperature) are under selection.
Data
We will use simulated data provided by Katie Lotterhos (Lotterhos et al. in prep). The initial data set is constituted of 509 individuals, 19 populations and 3084 SNP. It has 2 extra-columns: Population and Temperature measures. SNP are in columns: each row contains one value at each SNP locus (separated by spaces or tabulations) corresponding to the number of reference alleles: 0 means zero copies of the reference allele, 1 means one copy of the reference allele (i.e. heterozygote), and 2 means two copies of the reference allele.
Resources/Packages required
- PCAdapt: http://membres-timc.imag.fr/Michael.Blum/PCAdapt.html
- OutFLANK: https://github.com/whitlock/OutFLANK
Since OutFLANK is not yet on CRAN, you will need to install it from GitHub using the devtools R package. Additionally, OutFLANK depends on qvalue from Bioconductor, which must be installed beforehand.
install.packages("devtools")
library("devtools")
source("https://bioconductor.org/biocLite.R")
biocLite("qvalue")
install_github("whitlock/OutFLANK")Loading the required packages:
Section 1: Load the data
## [1] 509 3086Section 2: PCAdapt
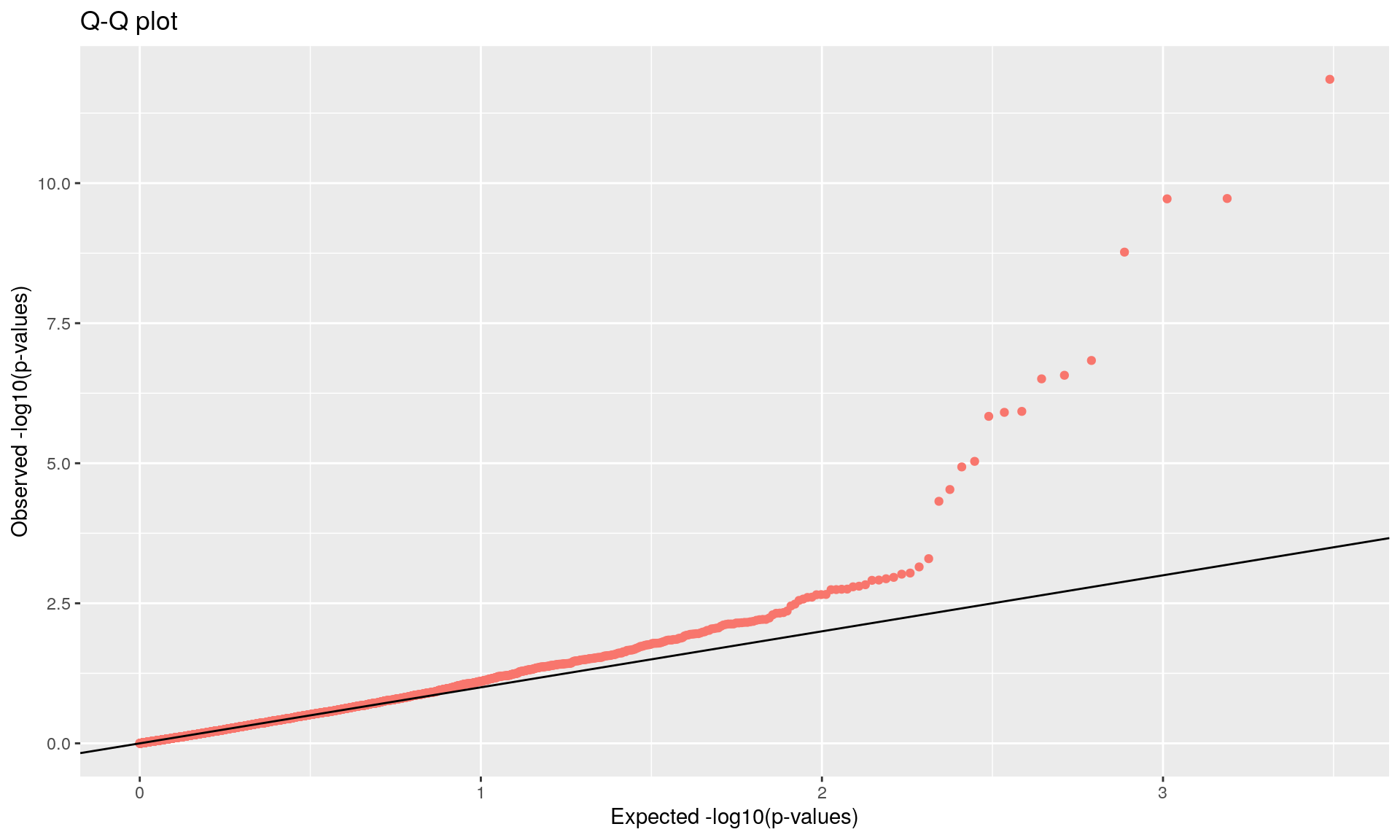
To run the function pcadapt(), the user should specify the number K of principal components (PC) to work with: first perform with a large number of principal components (e.g. higher than the number of populations), then use the ‘scree plot’ to chose the value of K. It displays the percentage of variance that is explained by each PC. The recommended value of K corresponds to the largest value of K before the plateau of ‘scree plot’ is reached. Then for a given SNP, a statistical test to define the SNP as outlier or not is based on the “loadings” that are defined as the correlation between the SNP and the PCs. The statistic test for detecting outlier SNPs is the Mahalanobis distance (between the K correlations of the SNP and each axis and mean correlations) and, which scaled by a constant, should have a chi-square distribution with K degrees of freedom under the assumption that there are no outlier. By default P-values of SNPs with a minor allele frequency smaller than 0.05 are not computed. A Manhattan plot displays log10 of the p-values. It is also possible to check the distribution of the p-values using a Q-Q plot. The authors suggest to use false discovery rate (q-value) to provide a list of outliers.
Note: PCAdapt expects the incoming matrix to have samples in columns and loci in rows. Because our data is the opposite, we need to transpose our data matrix with the
t()function.
## [1] 509 3084# PCAdapt requires a pcadapt_class object. You can convert a matrix to
# pcadapt_class with the read.pcadapt() function.
pca_genotype <- read.pcadapt(t(genotype))K <- 25
x <- pcadapt(pca_genotype, K = K)
plot(x, option = "screeplot") # 19 groups seems to be the correct value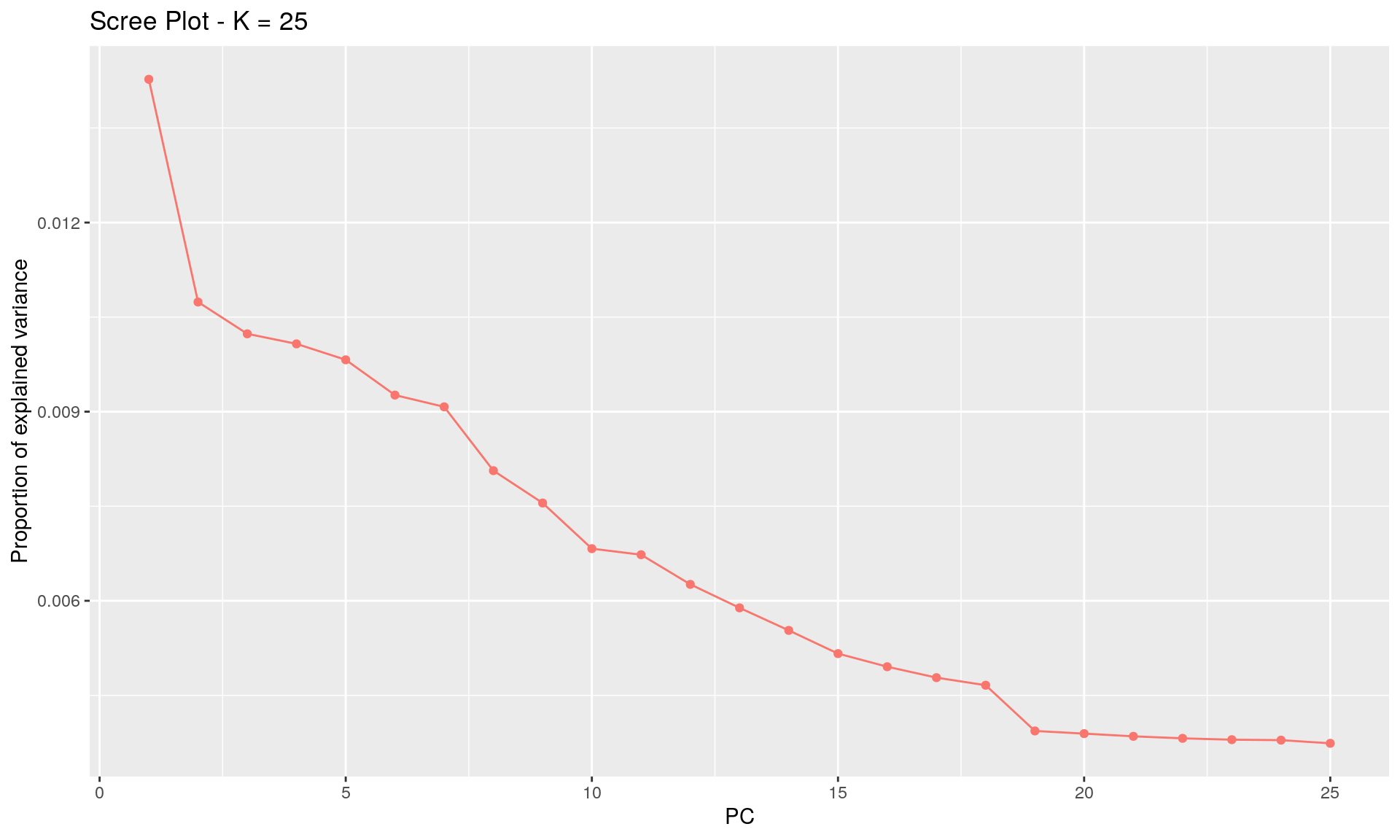
K <- 19
x <- pcadapt(pca_genotype, K = K, min.maf = 0)
summary(x) # numerical quantities obtained after performing a PCA## Length Class Mode
## scores 9671 -none- numeric
## singular.values 19 -none- numeric
## loadings 58596 -none- numeric
## zscores 58596 -none- numeric
## af 3084 -none- numeric
## maf 3084 -none- numeric
## chi2.stat 3084 -none- numeric
## stat 3084 -none- numeric
## gif 1 -none- numeric
## pvalues 3084 -none- numeric
## pass 3084 -none- numeric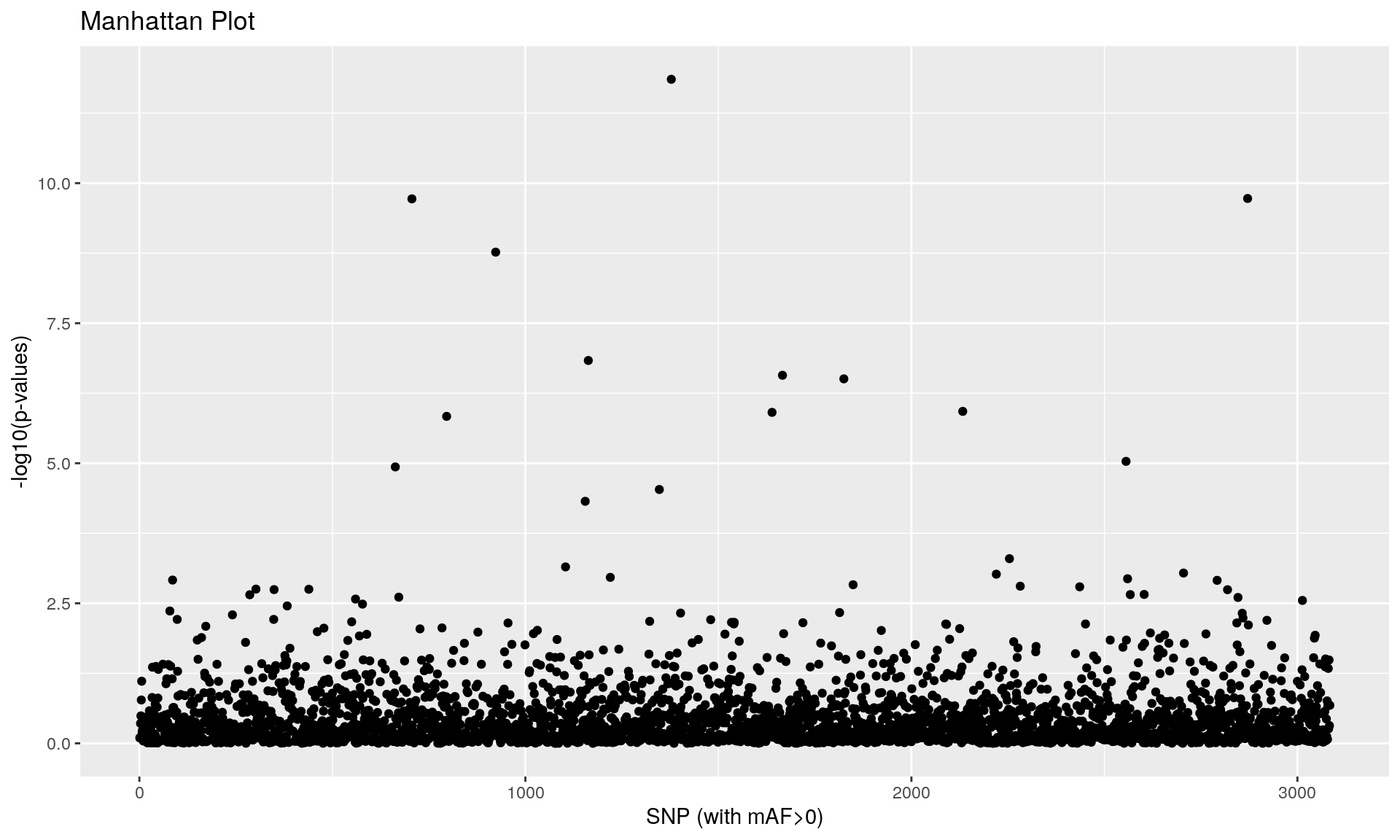
qval <- qvalue(x$pvalues)$qvalues
alpha <- 0.1
outliers_pcadapt <- which(qval < alpha)
print(outliers_pcadapt)## [1] 663 706 796 923 1155 1163 1347 1378 1639 1666 1825 2133 2556 2871## [1] 14alpha <- 0.05 # use of a more stringent threshold to detect outliers
outliers <- which(qval < alpha)
print(outliers)## [1] 663 706 796 923 1155 1163 1347 1378 1639 1666 1825 2133 2556 2871## [1] 14##section 3: OutFLANK (https://github.com/whitlock/OutFLANK)
A procedure to find Fst outliers based on an inferred distribution of neutral Fst: it uses likelihood on a trimmed distribution of Fst values to infer the distribution of Fst for neutral markers. This distribution is used to assign q-values to each locus to detect outliers loci potentially due to spatially heterogeneous selection. In practice, first the function MakeDiploidFSTMat() allows to calculate the appropriate input data frame among other parameters, Fst for each locus, and Fst without sampling size correction (FSTNoCorr). Then the function OutFLANK() estimate q-values and provides a list of outliers.
ind <- paste("pop", sel[, 1]) # vector with the name of population
locinames <- as.character(seq(ncol(genotype))) # vector with the name of loci
FstDataFrame <- MakeDiploidFSTMat(genotype, locinames, ind)## Calculating FSTs, may take a few minutes...plot(FstDataFrame$FST, FstDataFrame$FSTNoCorr, xlim = c(-0.01,0.3),
ylim = c(-0.01, 0.3), pch = 20)
abline(0, 1) # Checking the effect of sample size on Fst since FSTCoCorr will be used in the follow

OF <- OutFLANK(FstDataFrame, NumberOfSamples=19, qthreshold = 0.05,
RightTrimFraction = 0.05)
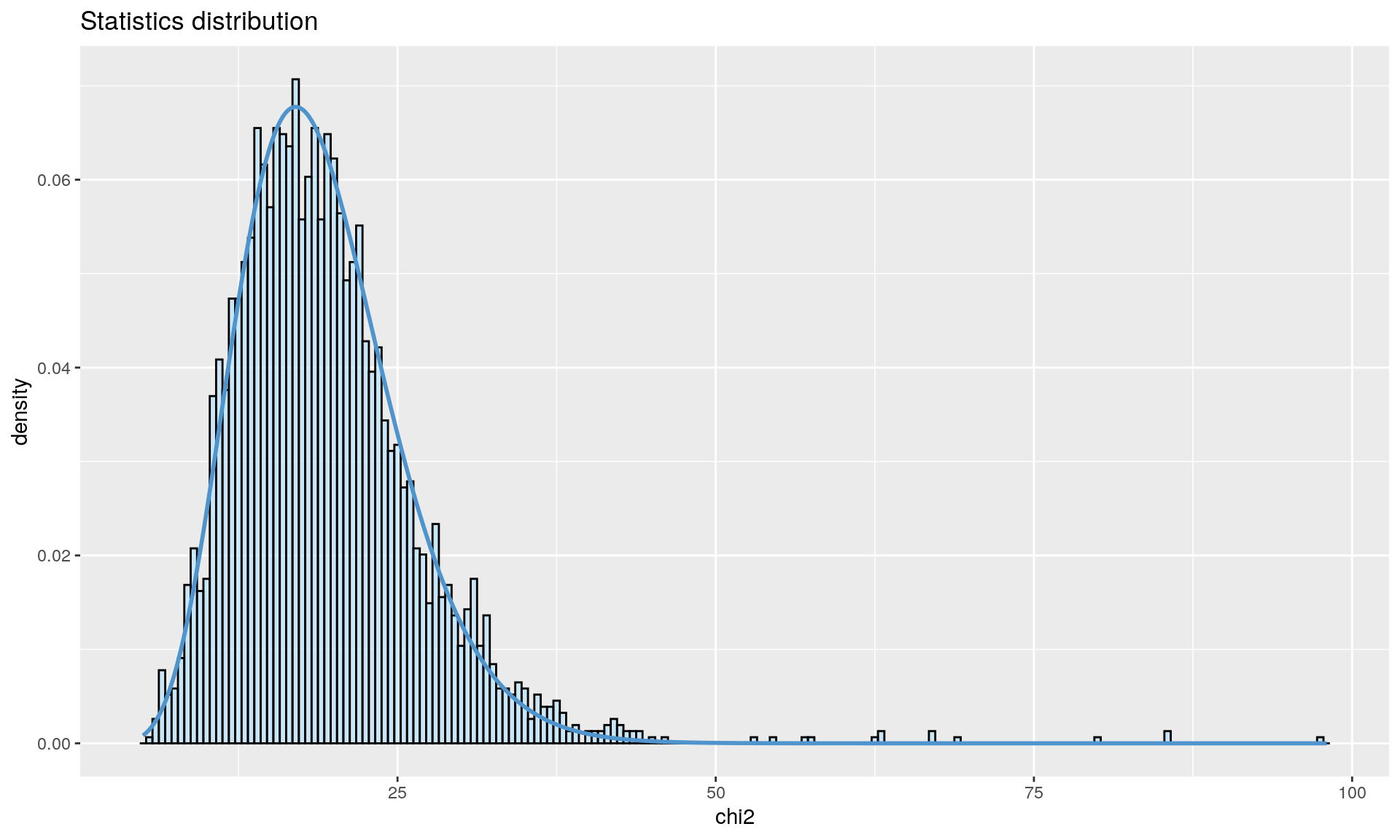
# Plot the ditribution of Fst with the chi squared distribution
OutFLANKResultsPlotter(OF, withOutliers = TRUE, NoCorr = TRUE, Hmin = 0.1,
binwidth = 0.005, Zoom = FALSE, RightZoomFraction = 0.05,
titletext = NULL)
## [1] 663 706 923 1163 1378 1639 1666 1825 2133 2556 2871
## 3084 Levels: 1 10 100 1000 1001 1002 1003 1004 1005 1006 1007 1008 ... 999## [1] 11Section 4: Logistic regression : linking outliers and temperature
We aim to test if the outliers detected with PCAdapt and OutFLANK (663 706 923 1163 1378 1639 1666 1825 2133 2556 2871) are correlated to the temperature. We use a GLM with a binomial error to model the probability to have the allele “A” out of the two alleles. We derive the relation for some of the shared outliers. You can do the test for all.
# We keep the outlier loci selected by both pcadapt and outflank
outliers <- outliers_pcadapt[outliers_pcadapt %in% outliers_OF]
length(outliers) # 11 outliers## [1] 11loc1 <- genotype[, outliers[1]]
temp <- sel$Temperature
loc1temp <- data.frame(loc1, temp)
mod <- glm(cbind(loc1, 2 - loc1) ~ temp, family = binomial)
summary(mod) # This locus is significantly correlated to temperature##
## Call:
## glm(formula = cbind(loc1, 2 - loc1) ~ temp, family = binomial)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.43957 -1.10354 0.09418 1.03271 2.62515
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.02085 0.06770 -0.308 0.758
## temp 0.27603 0.02603 10.606 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 869.59 on 508 degrees of freedom
## Residual deviance: 738.61 on 507 degrees of freedom
## AIC: 1011.6
##
## Number of Fisher Scoring iterations: 3loc2 <- genotype[, outliers[2]]
loc2temp <- data.frame(loc2, temp)
ggplot(loc2temp, aes(x = factor(loc2), y = temp)) +
geom_boxplot() +
xlab("Major allele count") +
ylab("Temperature (Centigrade)")
mod <- glm(cbind(loc2, 2 - loc2) ~ temp, family = binomial)
summary(mod) # This locus is significantly correlated to temperature##
## Call:
## glm(formula = cbind(loc2, 2 - loc2) ~ temp, family = binomial)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.19071 -1.25625 0.06401 1.21800 2.20092
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.02568 0.06552 -0.392 0.695
## temp 0.19104 0.02411 7.923 2.32e-15 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 837.64 on 508 degrees of freedom
## Residual deviance: 769.88 on 507 degrees of freedom
## AIC: 1059.5
##
## Number of Fisher Scoring iterations: 3# Test with a locus that is only selected by one method
loc7 <- genotype[, outliers_pcadapt[!outliers_pcadapt %in% outliers_OF][1]]
loc7temp <- data.frame(loc7, temp)
ggplot(loc2temp, aes(x = factor(loc7), y = temp)) +
geom_boxplot() +
xlab("Major allele count") +
ylab("Temperature (Centigrade)")
mod <- glm(cbind(loc7, 2 - loc7) ~ temp, family = binomial)
summary(mod) ## This locus is not significantly correlated to temperature##
## Call:
## glm(formula = cbind(loc7, 2 - loc7) ~ temp, family = binomial)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.84798 -1.59313 -0.06144 1.53467 1.73831
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 0.06980 0.06346 1.100 0.271
## temp -0.04202 0.02243 -1.874 0.061 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 802.15 on 508 degrees of freedom
## Residual deviance: 798.62 on 507 degrees of freedom
## AIC: 1106.2
##
## Number of Fisher Scoring iterations: 3Conclusions
- PCAdapt detected 14 outliers
- OutFLANK detected 11 outliers
- 11 outliers were detected in common
- Those common outliers are all significantly correlated with the temperatures as shown by Poisson regression. Such outliers can be potentially involved in local adaptation due to temperatures. However more analysis are necessary to confirm that they are outliers, and which allele is potentially under selection.
What’s next
Information on further analysis that could be done as LFFM (package LEA..).
Contributors
- Stephanie Manel (EPHE) (Author)
- Alicia Dalongeville (CEFE) (Author)
- Zhian Kamvar (reviewer)
#References
Duforet-Frebourg N, K Luu, G Laval, E Bazin, MGB Blum. (2016) Detecting genomic signatures of natural selection with principal component analysis: application to the 1000 Genomes data. Molecular Biology and Evolution (http://arxiv.org/abs/1504.04543)
Whitlock MC, Lotterhos KE (2015) Reliable Detection of Loci Responsible for Local Adaptation: Inference of a Null Model through Trimming the Distribution of Fst. The American Naturalist 186, S24-S36. http://www.jstor.org/stable/10.1086/682949
Session Information
This shows us useful information for reproducibility. Of particular importance are the versions of R and the packages used to create this workflow. It is considered good practice to record this information with every analysis.
## ─ Session info ───────────────────────────────────────────────────────────────────────────────────
## setting value
## version R version 3.6.1 (2019-07-05)
## os Debian GNU/Linux 9 (stretch)
## system x86_64, linux-gnu
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz Etc/UTC
## date 2019-09-16
##
## ─ Packages ───────────────────────────────────────────────────────────────────────────────────────
## package * version date lib source
## ape 5.3 2019-03-17 [1] CRAN (R 3.6.1)
## assertthat 0.2.1 2019-03-21 [1] CRAN (R 3.6.1)
## backports 1.1.4 2019-04-10 [1] CRAN (R 3.6.1)
## callr 3.3.1 2019-07-18 [1] CRAN (R 3.6.1)
## cli 1.1.0 2019-03-19 [1] CRAN (R 3.6.1)
## cluster 2.1.0 2019-06-19 [2] CRAN (R 3.6.1)
## colorspace 1.4-1 2019-03-18 [1] CRAN (R 3.6.1)
## crayon 1.3.4 2017-09-16 [1] CRAN (R 3.6.1)
## data.table 1.12.2 2019-04-07 [1] CRAN (R 3.6.1)
## DEoptimR 1.0-8 2016-11-19 [1] CRAN (R 3.6.1)
## desc 1.2.0 2018-05-01 [1] CRAN (R 3.6.1)
## devtools 2.2.0 2019-09-07 [1] CRAN (R 3.6.1)
## digest 0.6.20 2019-07-04 [1] CRAN (R 3.6.1)
## dplyr 0.8.3 2019-07-04 [1] CRAN (R 3.6.1)
## DT 0.8 2019-08-07 [1] CRAN (R 3.6.1)
## ellipsis 0.2.0.1 2019-07-02 [1] CRAN (R 3.6.1)
## evaluate 0.14 2019-05-28 [1] CRAN (R 3.6.1)
## fit.models 0.5-14 2017-04-06 [1] CRAN (R 3.6.1)
## fs 1.3.1 2019-05-06 [1] CRAN (R 3.6.1)
## ggplot2 * 3.2.1 2019-08-10 [1] CRAN (R 3.6.1)
## glue 1.3.1 2019-03-12 [1] CRAN (R 3.6.1)
## gtable 0.3.0 2019-03-25 [1] CRAN (R 3.6.1)
## htmltools 0.3.6 2017-04-28 [1] CRAN (R 3.6.1)
## htmlwidgets 1.3 2018-09-30 [1] CRAN (R 3.6.1)
## httr 1.4.1 2019-08-05 [1] CRAN (R 3.6.1)
## jsonlite 1.6 2018-12-07 [1] CRAN (R 3.6.1)
## knitr 1.24 2019-08-08 [1] CRAN (R 3.6.1)
## labeling 0.3 2014-08-23 [1] CRAN (R 3.6.1)
## lattice 0.20-38 2018-11-04 [2] CRAN (R 3.6.1)
## lazyeval 0.2.2 2019-03-15 [1] CRAN (R 3.6.1)
## lifecycle 0.1.0 2019-08-01 [1] CRAN (R 3.6.1)
## magrittr 1.5 2014-11-22 [1] CRAN (R 3.6.1)
## MASS 7.3-51.4 2019-03-31 [2] CRAN (R 3.6.1)
## Matrix 1.2-17 2019-03-22 [2] CRAN (R 3.6.1)
## memoise 1.1.0 2017-04-21 [1] CRAN (R 3.6.1)
## mgcv 1.8-28 2019-03-21 [2] CRAN (R 3.6.1)
## munsell 0.5.0 2018-06-12 [1] CRAN (R 3.6.1)
## mvtnorm 1.0-11 2019-06-19 [1] CRAN (R 3.6.1)
## nlme 3.1-140 2019-05-12 [2] CRAN (R 3.6.1)
## OutFLANK * 0.2 2019-09-15 [1] Github (whitlock/OutFLANK@e502e82)
## pcadapt * 4.1.0 2019-02-27 [1] CRAN (R 3.6.1)
## pcaPP 1.9-73 2018-01-14 [1] CRAN (R 3.6.1)
## permute 0.9-5 2019-03-12 [1] CRAN (R 3.6.1)
## pillar 1.4.2 2019-06-29 [1] CRAN (R 3.6.1)
## pinfsc50 1.1.0 2016-12-02 [1] CRAN (R 3.6.1)
## pkgbuild 1.0.5 2019-08-26 [1] CRAN (R 3.6.1)
## pkgconfig 2.0.2 2018-08-16 [1] CRAN (R 3.6.1)
## pkgload 1.0.2 2018-10-29 [1] CRAN (R 3.6.1)
## plotly 4.9.0 2019-04-10 [1] CRAN (R 3.6.1)
## plyr 1.8.4 2016-06-08 [1] CRAN (R 3.6.1)
## prettyunits 1.0.2 2015-07-13 [1] CRAN (R 3.6.1)
## processx 3.4.1 2019-07-18 [1] CRAN (R 3.6.1)
## ps 1.3.0 2018-12-21 [1] CRAN (R 3.6.1)
## purrr 0.3.2 2019-03-15 [1] CRAN (R 3.6.1)
## qvalue * 2.16.0 2019-05-02 [1] Bioconductor
## R6 2.4.0 2019-02-14 [1] CRAN (R 3.6.1)
## Rcpp 1.0.2 2019-07-25 [1] CRAN (R 3.6.1)
## remotes 2.1.0 2019-06-24 [1] CRAN (R 3.6.1)
## reshape2 1.4.3 2017-12-11 [1] CRAN (R 3.6.1)
## rlang 0.4.0 2019-06-25 [1] CRAN (R 3.6.1)
## rmarkdown 1.15 2019-08-21 [1] CRAN (R 3.6.1)
## robust 0.4-18.1 2019-07-02 [1] CRAN (R 3.6.1)
## robustbase 0.93-5 2019-05-12 [1] CRAN (R 3.6.1)
## rprojroot 1.3-2 2018-01-03 [1] CRAN (R 3.6.1)
## rrcov 1.4-7 2018-11-15 [1] CRAN (R 3.6.1)
## RSpectra 0.15-0 2019-06-11 [1] CRAN (R 3.6.1)
## scales 1.0.0 2018-08-09 [1] CRAN (R 3.6.1)
## sessioninfo 1.1.1 2018-11-05 [1] CRAN (R 3.6.1)
## stringi 1.4.3 2019-03-12 [1] CRAN (R 3.6.1)
## stringr 1.4.0 2019-02-10 [1] CRAN (R 3.6.1)
## testthat 2.2.1 2019-07-25 [1] CRAN (R 3.6.1)
## tibble 2.1.3 2019-06-06 [1] CRAN (R 3.6.1)
## tidyr 1.0.0 2019-09-11 [1] CRAN (R 3.6.1)
## tidyselect 0.2.5 2018-10-11 [1] CRAN (R 3.6.1)
## usethis 1.5.1 2019-07-04 [1] CRAN (R 3.6.1)
## vcfR 1.8.0 2018-04-17 [1] CRAN (R 3.6.1)
## vctrs 0.2.0 2019-07-05 [1] CRAN (R 3.6.1)
## vegan 2.5-6 2019-09-01 [1] CRAN (R 3.6.1)
## viridisLite 0.3.0 2018-02-01 [1] CRAN (R 3.6.1)
## withr 2.1.2 2018-03-15 [1] CRAN (R 3.6.1)
## xfun 0.9 2019-08-21 [1] CRAN (R 3.6.1)
## yaml 2.2.0 2018-07-25 [1] CRAN (R 3.6.1)
## zeallot 0.1.0 2018-01-28 [1] CRAN (R 3.6.1)
##
## [1] /usr/local/lib/R/site-library
## [2] /usr/local/lib/R/library